本文描述一套完整的大数据和机器学习模型开发环境建设方案,涵盖数据采集、存储、处理、模型训练、部署和推理。以下是详细的设计。
整体架构设计
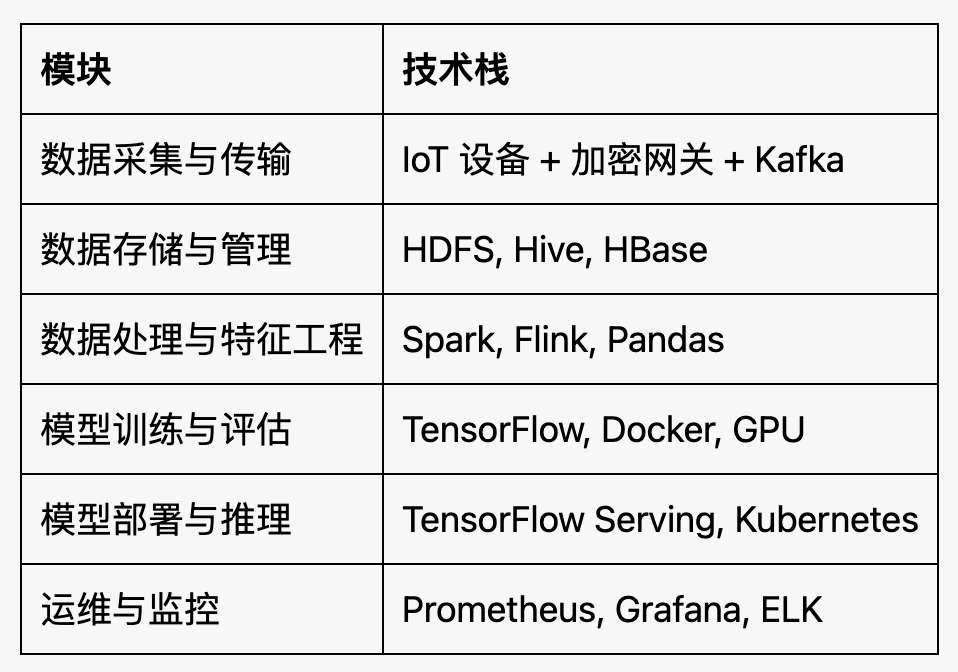
该系统主要分为以下模块:
- 数据采集与传输
- 数据存储与管理
- 数据处理与特征工程
- 模型训练与评估
- 模型部署与推理
- 运维与监控
1. 数据采集与传输
架构方案
- 终端设备:物联网设备通过加密网关上传数据。
- 消息队列:使用 Kafka 作为数据传输的核心组件,支持高吞吐量和分布式消息处理。
流程
- IoT 设备采集数据并通过加密网关上传。
- 网关将数据写入 Kafka 主题(Topic),分为:
- 原始数据主题(raw-data-topic)。
- 实时特征主题(real-time-feature-topic)。
- 数据通过 Kafka 保证分区和顺序性,便于后续处理。
2. 数据存储与管理
存储方案
- HDFS:作为主要分布式存储,存储清洗后的原始数据、离线数仓数据以及分布式特征仓库/样本库。
- NoSQL 数据库:如 HBase 或 Cassandra,用于存储高频查询的特征数据。
- Hive:基于 HDFS 的元数据管理,用于离线数据分析。
数据分层
- 原始数据层:Kafka 消息通过数据清洗后存入 HDFS,作为数据湖的一部分。
- 离线数仓层:构建基于 Hive 的离线数仓,用于大规模数据分析。
- 实时特征层:通过 Spark/Flink 流式处理后,存储在 HBase 或 Redis 中以支持快速查询。
3. 数据处理与特征工程
离线特征
- 数据清洗:从 Kafka 订阅数据,通过 Spark 批处理完成数据清洗和格式转换,保存到 HDFS。
- 特征工程:使用 Spark SQL 或 Python 工具(如 Pandas)构建离线特征,存储在分布式特征仓库中(支持 CSV、Hive 表等格式)。
实时特征
- 流式计算:通过 Spark Streaming 或 Flink 从 Kafka 订阅实时数据,构建时序类等动态特征。
- 存储方式:将实时生成的特征数据存储到 HBase 或 Redis,供模型实时推理使用。
分布式特征仓库
- 基于 HDFS 构建,支持多种格式(CSV、Hive 表、HBase 表)。
- 用于模型训练时的数据读取,同时支持不同计算节点的并发访问。
4. 模型训练与评估
训练环境
- 容器化部署:使用 Docker 对训练任务进行隔离,确保环境一致性。
- 算力调度:
- 每个 Docker 容器独享 GPU/CPU 资源。
- 使用 Kubernetes 或 Yarn 进行容器调度,动态分配资源。
- 存储:训练数据从 HDFS 读取,支持多种格式的访问(如 CSV、Hive 表、HBase)。
训练框架
- 使用 TensorFlow 作为主要训练框架,支持 GPU 加速。
- 支持分布式训练(如 TensorFlow 的分布式策略)。
- 通过分布式特征仓库加载数据,减少 I/O 瓶颈。
模型评估
- 训练完成后,进行模型评估,并将评估结果存入日志系统(如 ELK Stack 或 Prometheus)。
- 支持离线评估和在线评估。
5. 模型部署与推理
推理引擎
- 采用 TensorFlow Serving 或 TensorRT 进行推理服务部署。
- 使用 gRPC 或 REST API 提供接口,供其他微服务调用。
微服务架构
- 部署方式:基于 Docker 容器化部署,使用 Kubernetes 管理,支持容错和高可用。
- 灰度发布:通过 Kubernetes 的流量分配功能实现灰度发布。
- A/B 测试:支持在线多版本模型推理,实时对比模型效果。
实时推理支持
- 实时特征由 Kafka、Flink 或 Spark Streaming 计算,并写入 Redis/HBase。
- 推理服务从 Redis/HBase 查询实时特征,与模型进行匹配推理。
6. 运维与监控
监控体系
- 集群监控:通过 Prometheus + Grafana 监控 HDFS、Kafka、Spark/Flink 集群的性能和运行状态。
- 日志管理:使用 ELK Stack(Elasticsearch + Logstash + Kibana)收集和分析系统日志。
- 容器监控:通过 Kubernetes Dashboard 和 Prometheus 监控 Docker 容器的资源使用情况。
容灾与备份
- 数据备份:HDFS 数据定期备份到冷存储(如对象存储)。
- 高可用设计:
- Kafka 使用多副本机制。
- HDFS 开启 NameNode HA。
- Kubernetes 自动重启失败的容器。
技术选型总结
环境设计的特点
- 高扩展性:所有组件支持分布式部署,适应电网数据量的增长。
- 灵活性:支持离线和实时数据处理,满足不同场景需求。
- 高性能:利用 GPU 加速训练,Redis/HBase 提供快速特征查询。
- 高可用性:通过微服务化和容器化设计,支持容错和动态扩容。
- 可维护性:完善的监控和日志系统,便于问题定位和性能优化。