停电计划智能安排技术方案
1. 项目目标
建设一个调度域AI业务场景下的“停电计划智能安排模块”,旨在利用人工智能与优化算法,自动化处理停电需求,生成兼顾电网运行风险、作业效率、供电可靠性及项目管理等多重因素的优化停电计划与作业任务清单,显著提升停电计划编制的效率和质量。
2. 系统架构
建议采用微服务或模块化架构,便于未来扩展和维护。主要包含以下几个核心部分:
- 前端用户界面 (UI):负责用户交互,包括数据录入、计划导入、参数配置、结果展示和导出操作。
- 后端服务 (Backend Service):处理业务逻辑,包括API接口、用户管理、数据校验、任务调度等。
- 数据存储 (Data Storage):存储停电需求、电网拓扑数据、设备信息、历史停电记录、运行约束、生成的计划表、任务表等。
- AI调度优化引擎 (AI Scheduling & Optimization Engine):核心模块,负责执行智能排程算法。
- 数据接口层 (Data Interface Layer):用于与外部系统(如SCADA、GIS、资产管理系统、气象系统等)集成,获取必要的实时或基础数据。
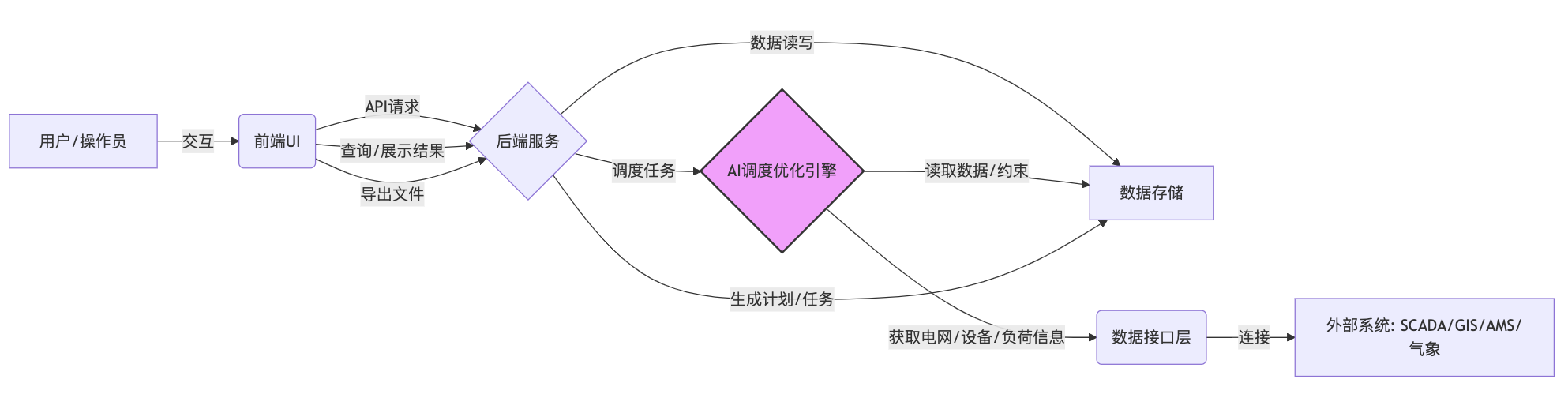
(架构图示意)
3. 功能模块设计
3.1 数据输入与管理模块
- 功能:
- 停电需求录入:提供结构化表单,录入单条停电需求,包括:申请单位、停电设备/线路、工作内容、计划开始/结束时间窗口、预估时长、影响范围、优先级、关联项目、特殊要求(如必须白天/夜间)等。
- 停电计划导入:支持从标准化模板文件(如Excel, CSV)批量导入停电需求或现有计划。需进行数据格式校验和清洗。
- 数据管理:提供对已录入/导入数据的查询、修改、删除功能。
- 技术要点:Web表单设计、文件上传与解析库(如Pandas for Python)、数据校验逻辑、数据库CRUD操作。
3.2 AI调度优化引擎
- 功能:这是系统的核心。接收经过处理的停电需求集合,结合电网运行数据和约束条件,运用算法生成优化后的停电计划表和作业任务表。
- 核心算法与逻辑:
- 数据整合:汇集停电需求、电网拓扑结构、设备参数、实时/预测负荷、线路潮流、N-1校核规则、特殊运行方式要求、保护定值信息、重要用户列表、历史停电数据、可用人力/资源、天气预报等。
- 约束建模:将各种限制条件形式化:
- 时间约束:工作窗口、禁止停电时段、节假日安排。
- 电网安全约束:基于潮流计算和N-1(或N-k)安全校核,确保任何计划的停电组合都不会导致线路过载、电压越限、稳定破坏等风险。需要嵌入简化的电网风险评估模型。
- 资源约束:考虑工作班组、特种车辆、备品备件的可用性。
- 逻辑约束:任务先后顺序、互斥关系(如不能同时停役某两条线路)、合并条件(同一区域、同一杆塔、同一变电站的任务可考虑合并)。
- 可靠性约束:尽量减少对用户的影响,特别是重要用户;避免短期内对同一区域/线路的重复停电。
- 优化目标:定义一个多目标的优化函数,可能包括:
- 最小化电网风险(关键指标,可通过风险评分量化)。
- 最大化计划完成率(按时完成需求的比例)。
- 最小化用户平均停电时间 (SAIDI/SAIFI影响)。
- 最小化重复停电次数/影响范围。
- 最大化任务合并度(提高作业效率)。
- 均衡负载(避免某些时段过于集中)。
- 算法选择:
- 启发式/元启发式算法:如遗传算法 (Genetic Algorithm)、模拟退火 (Simulated Annealing)、禁忌搜索 (Tabu Search)、粒子群优化 (PSO) 等。这类算法适合处理复杂、多约束、多目标的组合优化问题,能在合理时间内找到近似最优解。
- 约束规划 (Constraint Programming, CP):特别适合处理具有复杂逻辑约束的调度问题。
- 混合整数规划 (MIP):如果问题可以线性化,可以使用 Gurobi、CPLEX 等求解器,但可能对模型复杂度有限制。
- 机器学习辅助:可利用ML预测特定停电组合的风险等级,或预测作业时长,为优化算法提供更精确的输入。
- 技术要点:Python (配合优化库如
scipy.optimize,OR-Tools,DEAP等)、电力系统分析库(如pandapower)、数据库交互、可能需要高性能计算资源。
3.3 计划管理与输出模块
- 功能:
- 计划生成与展示:优化引擎计算完成后,生成结构化的停电计划表(按时间排序,包含停电时间、设备、工作内容、风险评估简报等)和停电任务表(按任务分配,包含具体作业步骤、所需资源、负责人等)。在UI上清晰展示。
- 时间维度聚合:提供按月、季、年等时间范围筛选、汇总和展示计划的功能。
- 结果评估:展示优化结果的关键指标,如预期风险水平、影响用户数、合并任务数等,供用户评估。
- 人工调整接口 (可选但推荐):允许有经验的调度员在自动生成的基础上进行微调,并重新进行风险校核。
- 文件导出:支持将生成的计划表和任务表导出为常用格式(如Excel, CSV, PDF)。
- 技术要点:数据查询与聚合 (SQL Group By)、报表生成库、文件导出库 (如
openpyxl,reportlabfor Python)。
3.4 用户界面模块 (UI)
- 功能:提供图形化界面,方便用户进行所有操作。
- 设计原则:简洁直观、易于操作、信息展示清晰。
- 技术栈示例:React, Vue, Angular 等现代前端框架。
4. 数据需求
- 基础数据:
- 电网拓扑结构(GIS数据或标准格式文件)
- 设备台账(变压器、开关、线路参数、保护定值)
- 重要用户信息及供电路径
- 标准作业流程与预估时长
- 人力资源与可用设备清单
- 动态/准动态数据:
- 实时/预测负荷曲线
- 天气预报信息
- 外部系统约束(如重大活动保电要求)
- 实时运行方式(可能需要从SCADA获取)
- 输入数据:
- 停电需求(来自各部门)
- 现有或历史停电计划
5. 技术栈建议
- 后端:Python (Flask/Django) 或 Java (Spring Boot)
- 前端:React / Vue.js / Angular
- 数据库:PostgreSQL / MySQL (关系型数据库) + 可能的 NoSQL 数据库 (如 Redis 用于缓存)
- AI/优化库:Python 生态 (Pandas, NumPy, Scipy, OR-Tools, DEAP, scikit-learn, pandapower)
- 部署:Docker, Kubernetes
6. 实施步骤建议
- 需求详细化与设计:明确所有功能细节、数据格式、接口规范、风险评估模型。
- 环境准备与技术选型:确定最终技术栈,准备开发、测试、生产环境。
- 数据准备与集成:收集、清洗、整理所需的基础数据和动态数据,开发数据接口。
- 核心引擎开发与测试:优先开发AI调度优化引擎,进行算法选型、建模、编码和单元测试,使用模拟数据或历史数据验证效果。这是项目关键。
- 后端服务与API开发:开发支撑业务逻辑的后端服务和API接口。
- 前端界面开发:开发用户交互界面。
- 集成测试:将各模块集成,进行端到端的功能测试和性能测试。
- 用户验收测试 (UAT):邀请最终用户(调度员)进行试用,收集反馈并进行调整。
- 部署上线与培训:部署系统到生产环境,对用户进行培训。
- 持续优化与维护:根据用户反馈和实际运行效果,持续优化算法模型和系统功能。
7. 关键挑战与风险
- 数据质量与完整性:准确、全面的电网数据是AI模型有效性的基础。
- 算法复杂度与性能:调度优化问题通常是NP-hard,需要平衡解的质量和计算时间。
- 风险评估模型的准确性:如何精确量化不同停电组合的电网风险是核心难点。
- 与现有系统集成:与其他调度自动化系统(SCADA, EMS, DMS)的顺畅集成可能存在技术挑战。
- 用户接受度:需要让经验丰富的调度员信任并有效使用AI辅助决策工具。
8. 预期收益
- 效率提升:大幅缩短停电计划编制时间,解放人力。
- 风险降低:通过系统性评估,降低因计划不当导致的电网运行风险。
- 可靠性提高:优化停电安排,减少用户停电次数和时间。
- 标准化与透明化:使停电计划过程更加规范、透明、可追溯。