配网终端设备故障分类接口逻辑
1. 系统概述
本系统旨在实时接收配网终端设备上报的遥测(电流、电压、功率等)和遥信(开关状态、定值等)数据,并根据预设的优先级和逻辑,利用规则和机器学习模型对设备故障进行自动分类(如失压、短路、接地、过载、断路等),最终输出分类结果。系统采用分层分类策略,优先处理遥信定值异常触发的分类,其次处理遥测数据异常触发的分类,最后进行规则化的汇总分类。
2. 系统架构与功能模块
系统可以设计为基于微服务的架构,以提高灵活性、可扩展性和可维护性。主要功能模块如下:
-
数据接入模块 (Data Ingestion Service):
- 功能: 负责接收来自配网终端设备的遥测和遥信数据。可能通过MQTT、HTTP、TCP或其他协议接入。
- 职责: 数据接收、初步校验、格式转换,并将数据推送至消息队列或直接传递给后续处理模块。
-
数据预处理与存储模块 (Data Preprocessing & Storage Service):
- 功能: 对接收到的原始数据进行清洗、转换、时间戳对齐、特征工程(如果模型需要)等预处理。
- 职责: 将处理后的数据存储到合适的数据库(如时序数据库InfluxDB/TimescaleDB用于存储时序数据,关系型数据库或NoSQL数据库用于存储设备元数据和分类结果)。
-
实时数据流处理/编排模块 (Real-time Stream Processing / Orchestration Engine):
- 功能: 系统的核心调度单元。订阅预处理后的数据流,根据定义的分类逻辑进行判断和任务分发。
- 职责:
- 实时监控遥信数据,判断是否存在“定值异常”。
- 若遥信定值正常,则监控遥测数据,判断是否存在“遥测数据异常”(需要定义异常判断规则,如阈值、突变、统计异常等)。
- 根据判断结果,按优先级调用相应的故障分类模型服务。
- 管理分类流程的状态,确保按逻辑顺序执行。
- 处理模型服务的返回结果,决定是输出结果还是流转到下一个模型。
-
遥信定值异常检测模块 (Teleindication Setpoint Anomaly Detection):
- 功能: 内嵌于编排模块或作为一个独立的微服务。
- 职责: 根据配置的规则或阈值,判断传入的遥信数据是否存在定值异常。
-
遥测数据异常检测模块 (Telemetry Data Anomaly Detection):
- 功能: 内嵌于编排模块或作为一个独立的微服务。
- 职责: 分析遥测数据流,根据预设规则(如超过阈值、变化率异常、与历史模式偏离等)判断遥测数据是否异常。
-
故障分类模型服务 [1] (Fault Classification Model Service [1] - Java):
- 功能: 实现第一优先级分类逻辑(基于规则)。
- 职责: 接收编排器传递的遥测和遥信数据,执行分类规则。如果识别出明确的第一优先级故障类型,则返回结果;否则返回无法识别的指示。以API形式(如RESTful API)提供服务。
-
故障分类模型服务 [2] (Fault Classification Model Service [2] - Algorithm):
- 功能: 实现第二优先级分类逻辑(基于机器学习算法)。
- 职责: 主要接收编排器传递的遥测数据(可能也需要部分遥信数据作为辅助特征),执行机器学习分类算法。如果识别出明确的第二优先级故障类型,则返回结果;否则返回无法识别的指示。以API形式提供服务。
-
故障分类模型服务 [3] (Fault Classification Model Service [3] - Java Catch-all):
- 功能: 实现第三优先级分类逻辑(基于简单规则的Catch-all)。
- 职责: 接收编排器传递的遥测和遥信数据,根据预设的简单规则(如电压过低/过高归为电压故障,电流过大归为电流故障),将无法被前两级模型识别的异常归类到“电压故障”或“电流故障”两大类。以API形式提供服务。
-
结果存储与查询模块 (Result Storage & Query Service):
- 功能: 存储最终的故障分类结果。
- 职责: 提供接口供存储分类结果(包括故障类型、发生时间、相关数据快照、置信度等),并支持对历史故障记录的查询、统计和展示。
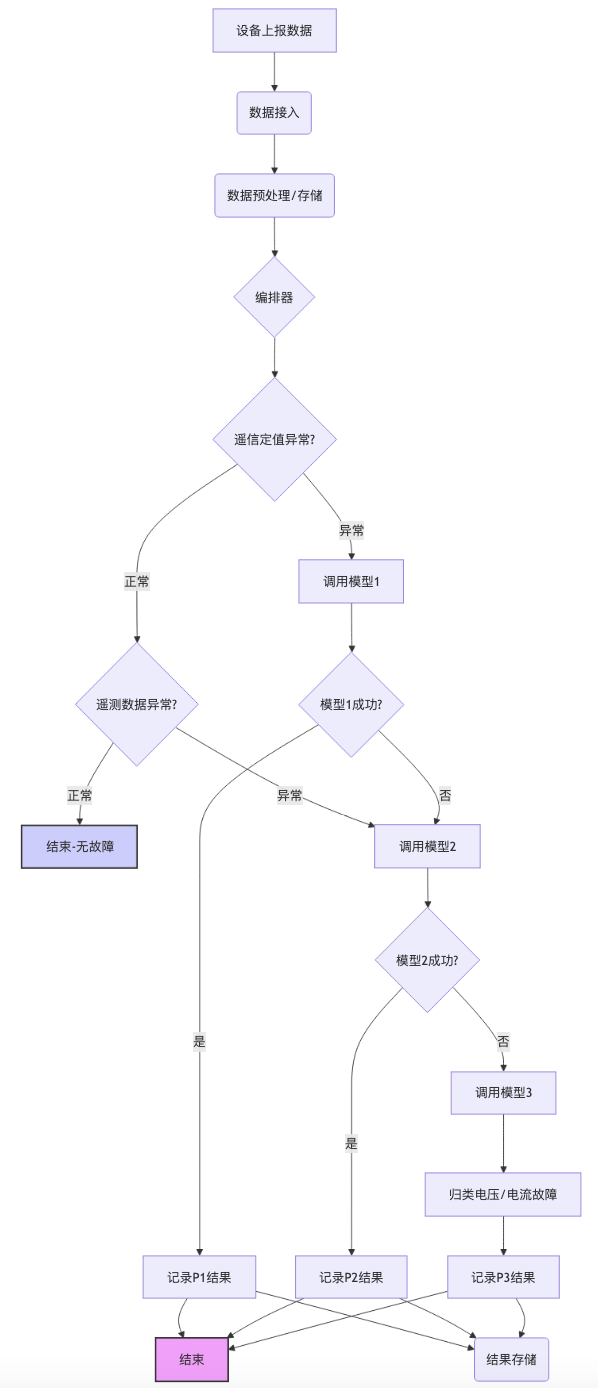
3. 模块交互关系与数据流
- 配网终端设备 -> 数据接入模块 (上报遥测/遥信数据)
- 数据接入模块 -> 数据预处理与存储模块 (推送原始数据)
- 数据预处理与存储模块 -> (存储数据) & -> 实时数据流处理/编排模块 (推送处理后的数据流)
- 编排模块 分析数据流:
- 调用 遥信定值异常检测模块 判断遥信定值。
- IF 遥信定值异常:
- 编排模块 -> 模型服务[1] (传递遥测+遥信数据)
- 模型服务[1] -> 编排模块 (返回结果: P1故障类型 / 无法识别)
- IF 模型[1]返回P1故障:
- 编排模块 -> 结果存储与查询模块 (记录结果) -> 流程结束
- ELSE (模型[1]无法识别):
- 编排模块 -> 模型服务[2] (传递遥测数据,可能+遥信) -> 转至步骤 5
- ELSE (遥信定值正常):
- 编排模块 调用 遥测数据异常检测模块 判断遥测数据。
- IF 遥测数据异常:
- 编排模块 -> 模型服务[2] (传递遥测数据) -> 转至步骤 5
- ELSE (遥测数据也正常):
- 流程结束 (本次数据无故障)
- (来自步骤4的两个分支) 编排模块与**模型服务[2]**交互:
- 模型服务[2] -> 编排模块 (返回结果: P2故障类型 / 无法识别)
- IF 模型[2]返回P2故障:
- 编排模块 -> 结果存储与查询模块 (记录结果) -> 流程结束
- ELSE (模型[2]无法识别):
- 编排模块 -> 模型服务[3] (传递遥测+遥信数据)
- 编排模块与**模型服务[3]**交互:
- 模型服务[3] -> 编排模块 (返回结果: 电压故障 / 电流故障)
- 编排模块 -> 结果存储与查询模块 (记录结果) -> 流程结束
4. Mermaid 流程图
5. 技术选型建议 (可选)
- 消息队列: Kafka, RabbitMQ, Pulsar (用于数据接入和模块间解耦)
- 数据存储:
- 时序数据: InfluxDB, TimescaleDB (PostgreSQL 插件)
- 分类结果/元数据: PostgreSQL, MySQL, MongoDB
- 流处理/编排: Flink, Spark Streaming, Kafka Streams, 或者使用 Spring Cloud Stream/State Machine 等框架自建编排服务。
- 模型服务:
- Java 服务: Spring Boot
- 算法服务: Python (Flask/FastAPI) + 相关机器学习库 (Scikit-learn, TensorFlow, PyTorch)
- 部署: Docker, Kubernetes (用于容器化和集群管理)
6. 注意事项
- 异常定义: 需要明确定义“遥信定值异常”和“遥测数据异常”的具体规则和阈值。
- 模型接口: 定义清晰统一的模型服务API接口规范,方便编排器调用。
- 性能: 考虑实时数据处理的性能要求,选择合适的流处理技术和数据库。
- 监控: 对整个系统各模块的运行状态、处理延迟、资源消耗进行监控。
- 可配置性: 将规则、阈值、模型路径等设计为可配置项,方便后续调整优化。
这个方案提供了一个清晰的架构和流程,您可以根据实际团队技术栈和业务细节进行调整和细化。