新的设备故障分类需求:
- 遥信异常,基本就是有异常(配错除外,那是运维自己工作没做好)。
- 遥测异常,此时遥信定值不一定发生突变,可能异常没那么严重。
- 在工作上,如果遥信异常,我们要当作故障对待,结合遥测、遥信数据,用机器学习模型进行分类。
- 对每批上报的遥测数据,也要用机器学习模型进行监控(比如lstm),发现潜在的异常(这些异常可能暂时不会触发遥信)。
- 重点在于分析ftu设备(含ftu管理的设备如断路器、开关)的异常,但设备异常与线路异常信号,既然难以区分,就不用去区分,一视同仁对待。
- 分类的目标(从精到粗):第一个目标是一期分类xcel里定义的几大类目标;第二个目标是在线故障分类表定义的目标;第三个目标(catchall)就是电压、电流异常,子类就是哪一相的电压、电流异常。
这是一个非常有价值且实际的应用场景。结合您的需求和提供的数据特点,我为您设计一个基于机器学习/深度学习的技术方案,分步骤实现您的目标。
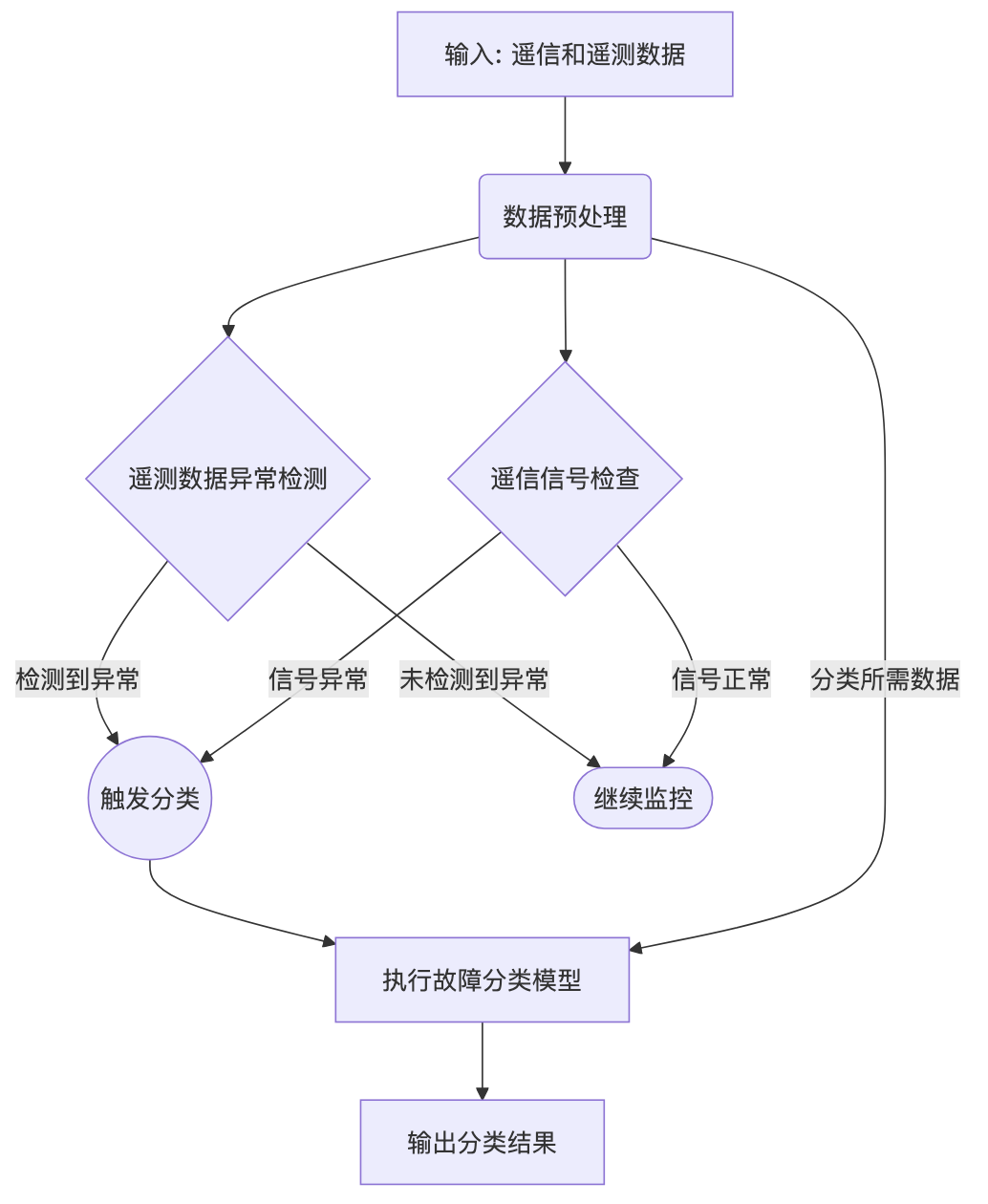
核心思路:
- 双模驱动: 建立两个核心模型:
- 异常检测模型(针对遥测数据): 持续监控遥测数据,提前发现潜在的、未触发遥信的异常波动。
- 故障分类模型(结合遥信和遥测): 当遥信报警或异常检测模型报警时,启动此模型,利用报警时刻前后的遥测数据和当前的遥信状态,对故障/异常进行精准分类。
- 数据融合: 有效结合离散的遥信(事件信号)和连续的遥测(时序数值)数据。
- 分层分类: 按照您定义的优先级(外部Excel -> 在线故障表 -> 电压/电流异常)进行分类。
技术方案详解:
第一步:数据准备与预处理
-
数据接入与整合:
- 建立数据管道,实时或准实时接收来自FTU上报的遥信和遥测数据。
- 确保每条数据都有精确的时间戳,并且遥信和遥测数据能按时间戳对齐。
- 将同一时间点(或一个短时间窗口内)的遥信(200+)和遥测(10+)数据关联起来,形成一个宽表或结构化数据记录。
-
数据清洗:
- 处理缺失值:
- 遥测数据:可使用均值/中位数填充、前向/后向填充,或更复杂的插值方法(如线性插值、样条插值)。考虑到时序性,基于时间窗口的填充可能更优。
- 遥信数据:通常是状态位,缺失可能意味着通信中断或状态未知,可以作为一个特殊状态处理或根据业务逻辑判断。
- 处理异常值/噪声:对遥测数据进行异常值检测(如3-sigma法则、箱线图),但要小心区分真实故障和噪声。可能需要结合业务知识设定合理阈值。
- 处理缺失值:
-
特征工程:
- 遥测数据:
- 归一化/标准化: 将不同量纲的遥测指标(电压、电流、功率)缩放到相似范围(如0-1或均值为0标准差为1),这对于大多数ML/DL模型是必要的。常用方法:Min-Max Scaling, Z-Score Standardization。
- 时间窗口特征: 对于时序模型(如LSTM),将遥测数据构造成固定长度的时间窗口序列(例如,过去10分钟的数据,每10秒一个点,形成60个时间步长的序列)。
- 统计特征: 对于非时序模型(如分类器),可以从时间窗口中提取统计特征,如均值、标准差、最大值、最小值、趋势(斜率)、波动率等。
- 遥信数据:
- 编码: 遥信数据通常是0/1(正常/异常)或多状态值。可以直接使用(0/1),或者如果有多状态,可以使用独热编码(One-Hot Encoding)。
- 状态变化特征: 可以增加特征表示某个遥信信号是否在最近一个时间窗口内发生了从正常到异常的变化。
- 遥测数据:
-
标签体系构建(关键步骤):
- 整合分类目标: 汇总您提到的三个优先级来源的故障/异常类型,建立一个统一的、层级化的标签体系。
- 第一层(最高优先级): 来自Excel定义的具体故障类型(如:对时异常、零序电流异常、二次侧采样异常等)。
- 第二层: 来自在线故障分类表 (
ftu-fault-types) 定义的类型。 - 第三层(Catch-all): 电压异常(UA/UB/UC/UAB/UBC/UCA)、电流异常(IA/IB/IC/I0)。
- 历史数据标注: 这是监督学习的核心。需要运维专家或历史故障记录,对历史数据中的事件(特别是遥信报警时段)进行标注,打上对应的故障标签。这是一个耗时但至关重要的步骤。如果完全没有历史标签,可以考虑先从未标注数据开始做异常检测,然后对检测出的异常进行人工标注,逐步积累训练数据。
- 整合分类目标: 汇总您提到的三个优先级来源的故障/异常类型,建立一个统一的、层级化的标签体系。
第二步:模型设计与训练
-
模型一:基于遥测数据的异常检测模型 (LSTM Autoencoder / 其他时序异常检测模型)
- 目标: 实现需求4,监控遥测数据,发现潜在异常。
- 输入: 经过预处理和窗口化的遥测数据序列。
- 模型选择:
- LSTM Autoencoder (推荐): 训练一个LSTM自动编码器,学习正常运行模式下遥测数据的时序规律。模型尝试重建输入序列,对于正常数据,重建误差低;对于偏离正常模式的数据(潜在异常),重建误差会显著升高。设定一个合适的重建误差阈值来判断异常。
- 其他模型: Isolation Forest, One-Class SVM (应用于窗口统计特征), 或基于统计的方法 (如动态阈值)。
- 训练: 使用大量标记为“正常”的历史遥测数据序列进行训练。
- 输出: 每个时间点的异常得分。当得分超过阈值时,产生一个“潜在异常”告警。
-
模型二:基于遥信+遥测的故障分类模型 (监督学习分类器)
- 目标: 实现需求3和需求6,当发生遥信报警或异常检测模型报警时,进行故障分类。
- 触发时机:
- 任意一个或多个关心的遥信指标变为“异常”状态。
- 模型一(异常检测)的异常得分超过阈值。
- 输入:
- 触发时刻的遥信状态快照: 所有200多个遥信指标的当前状态(0或1)。
- 触发时刻前一段时间窗口的遥测数据: 例如,触发前5-10分钟的遥测数据序列或其统计特征。这有助于捕捉故障发生前的变化和故障发生时的具体表现。
- 模型选择:
- 梯度提升树 (XGBoost, LightGBM, CatBoost): 对表格数据(包括数值和类别特征)效果好,鲁棒性强,能处理特征间的复杂交互,通常是首选。
- 随机森林 (Random Forest): 另一种强大的集成模型。
- 深度神经网络 (MLP/CNN/Transformer): 如果遥测数据使用原始序列作为输入,可以考虑结合CNN(提取局部模式)或Transformer(捕捉长距离依赖)处理遥测序列,然后与遥信特征融合,输入到全连接层进行分类。MLP可以直接处理拼接后的特征向量。
- 训练: 使用经过人工标注的历史故障事件数据进行训练。每个样本包含触发时的遥信快照、触发前的遥测窗口数据,以及对应的故障标签(来自整合后的标签体系)。需要处理类别不平衡问题(某些故障可能很罕见),可以采用过采样(SMOTE)、欠采样或代价敏感学习。
- 输出: 预测的故障类别(按照优先级体系),以及可能的置信度。
第三步:系统集成与部署
- 工作流设计:
- 数据流进入预处理模块。
- 预处理后的遥测序列持续送入异常检测模型。
- IF 异常检测模型报警 OR 接收到遥信异常信号:
- 触发故障分类模型。
- 提取当前遥信快照和触发点之前的遥测数据窗口。
- 故障分类模型进行预测。
- 输出分类结果(如:P1级-零序电流异常,或 P3级-UA电压异常)。
- ELSE: 继续监控。
- 部署方案:
- 离线训练: 模型需要使用历史数据进行离线训练和调优。
- 在线推理:
- 将预处理逻辑和训练好的模型封装成服务。
- 可以部署在边缘计算节点(如果FTU算力允许且需要低延迟响应)或中心服务器上。
- 考虑使用流处理框架(如Kafka + Flink/Spark Streaming)处理实时数据流。
- 模型服务化框架(如TensorFlow Serving, TorchServe, MLflow)方便模型部署和管理。
- 结果展示与应用:
- 将模型的输出(潜在异常告警、故障分类结果)整合到现有的监控平台或运维工单系统中。
- 提供清晰的告警信息,包括时间、涉及的设备/线路(FTU标识)、检测到的异常类型(分类结果)、置信度以及相关的遥测/遥信数据快照,辅助运维人员决策。
技术选型建议:
- 编程语言: Python 是主流选择,生态完善。
- 核心库:
- 数据处理:Pandas, NumPy
- 机器学习:Scikit-learn (通用ML), XGBoost, LightGBM (梯度提升)
- 深度学习:TensorFlow/Keras 或 PyTorch (LSTM, MLP, CNN等)
- 时序处理:tslearn, darts (可选)
- 部署: Docker, Kubernetes, MLflow, TF Serving/TorchServe。
需要注意的关键点:
- 数据质量和标签质量: 这是整个方案成功的基石。需要投入精力进行数据清洗和准确标注。
- 模型可解释性: 对于故障诊断,了解模型为什么做出某个分类判断很重要。可以采用 SHAP 或 LIME 等方法来解释模型预测。
- 模型迭代与更新: 电网运行状况可能变化,新的故障模式可能出现。需要定期使用新数据重新训练和评估模型,保持其有效性。
- 处理需求5(设备与线路不区分): 该方案天然满足此需求。模型基于FTU上报的信号和测量数据进行分析,只要是该FTU能感知到的异常(无论是其自身、管理的设备还是线路),都会被纳入分析范围,模型分类的目标是现象(如电压异常、电流异常、通信异常等),而非物理定位到具体是FTU坏了还是开关坏了(虽然某些故障类型可能强相关)。
- 计算资源: 深度学习模型(特别是LSTM)训练可能需要较多计算资源(GPU)。在线推理的资源需求取决于模型复杂度和数据吞吐量。
这个方案提供了一个比较全面和现代化的技术路径。您可以根据实际的资源、数据可用性和团队技术栈进行调整和细化。